
Add to Cart
Network Packet Slicing Broker Removing Payload Data from Sensitive
Data Packets
Packet Slicing
Packet Slicing is a network data processing technique used to
segment or extract specific parts of a data packet for analysis,
storage, or monitoring. This method is particularly useful in
scenarios where only certain information within a packet is needed,
reducing the amount of data that needs to be processed or stored.
By removing payload data from packets and leaving only the header
information, policy-based packet slicing (64-1518 bytes optional)
of the raw data, and the traffic output policy can be implemented
based on user configuration, the network monitoring switch can send
more data across a given link to the tool. The tool receives more
condensed network data for analysis, increasing efficiency and
utilization.
Packet Slicing Value
1- Slicing the sensitive information from the packet, avoid the
data leakage.
2- Removing payload data leaving header information
3- Reduces tool throughput
4- Save disk storage space
5- Improving performance and data retention
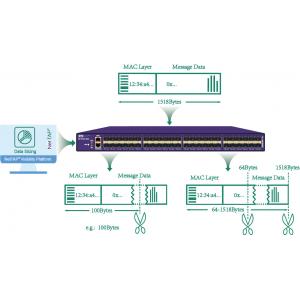
As shown in the above, the length of 1518 bytes of the original
message for storage and analysis of actual users only need to store
or work analysis of the content of the message the first 100 bytes,
storage and analysis of the whole flow, not only increase the cost
of storage equipment, will also reduce the efficiency of analysis
system, so the application of the network packet broker, biopsy to
the original message output after processing, retain information to
meet the needs of users, can reduce the output flow, improve the
working efficiency of the analysis system, reduce the user cost of
storage system. The network packet broker for packet slice options
range from 64 to 1518 bytes, allowing users to customize slice
values to meet different analysis requirements.
Beside packet slicing, the network packet broker has as well as
advanced features such as Load Balancing Header Stripping,
Deduplication, Data Masking, Packet Slicing, Time-Stamping, Data
Capture and De-Fragmentation.
Data De-duplication is a popular and popular storage technology
that optimizes storage capacity.It eliminates redundant data by
removing duplicate data from the dataset, leaving only one copy.As
shown in the figure below.This technology can greatly reduce the
need for physical storage space to meet the growing demand for data
storage.Dedupe technology can bring many practical benefits, mainly
including the following aspects:
(1) Meet ROI(Return On Investment)/TCO(Total Cost of Ownership)
requirements;
(2) The rapid growth of data can be effectively controlled;
(3) Increase effective storage space and improve storage
efficiency;
(4) Save the total storage cost and management cost;
(5) Save the network bandwidth of data transmission;
(6) Save operation and maintenance costs such as space, power
supply and cooling.
Dedupe technology is widely used in data backup and archiving
systems, because there are a lot of duplicate data after multiple
backups of data, which is very suitable for this technology.In
fact, dedupe technology can be used in many situations, including
online data, near-line data, and offline data storage systems. It
can be implemented in file systems, volume managers, NAS, and
sans.Dedupe can also be used for data disaster recovery, data
transmission and synchronization, as a data compression technology
can be used for data packaging.Dedupe technology can help many
applications reduce data storage, save network bandwidth, improve
storage efficiency, reduce the backup window, and save costs.
Dedupe has two main dimensions: deduplocation ratios and
performance.Dedupe performance depends on the specific
implementation technology, while Dedupe rate is determined by the
characteristics of the data itself and application patterns, as
shown in the table below.Storage vendors currently report
deduplication rates ranging from 20:1 to 500:1.
High deduplication rate | Low deduplication rate |
Data created by the user | Data from the natural world |
Data low rate of change | Data high rate of change |
Reference data, inactive data | Active data |
Low data change rate application | High data change rate application |
Full data backup | Incremental data backup |
Data long-term storage | Data short-term storage |
Wide range of data applications | Small range of data applications |
Continuous data business processing | General data business processing |
Small data segmentation | Big data segmentation |
Elongate data segmentation | Fixed length data segmentation |
Data content perceived | Data content unknown |
Time data deduplication | Spatial data deduplication |
Dedupe Implementation Points
Various factors should be considered when developing or applying
Dedupe technology, as these factors directly affect its performance
and effectiveness.
(1) What: What data are de-weighted?
(2) When: When will the weight be eliminated?
(3) Where: Where is the weight elimination?
(4) How: How to reduce the weight?
Dedupe Key Technology
Deduplication process of storage system in general is this: first
of all the data file is divided into a set of data, for each block
of data to calculate the fingerprint, and then based on fingerprint
Hash search keywords, matching indicates the data for the duplicate
data blocks, only stores data block index number, otherwise it
means the data block is the only piece of a new, storage of data
block and create relevant meta information.Thus, a physical file in
the storage system corresponds to a logical representation of a set
of FP metadata.When reading the file, first read the logical file,
then according to the FP sequence, take out the corresponding data
block from the storage system, restore the copy of the physical
file.It can be seen from the above process that the key
technologies of Dedupe mainly include file data block segmentation,
data block fingerprint calculation and data block retrieval.
(1) File data block segmentation
(2) Data block fingerprint calculation
(3) Data block retrieval
Network Packet Broker Specification and Module Type
Component type | Product Model | Basic Parameter | Remarks |
Chassis | NTCA-CHS-7U7S-DC | Height:7U,7 slots, ATCA Chassis, double star 100G backplane, 3 high voltage DC(240VDC~280VDC) input,3* 2+1 redundant 3000W power modular | Must choose one |
NTCA-CHS-7U7S-AC | Height:7U,7 slots, ATCA Chassis, double star 100G backplane, 3 high voltage AC(240VDC~280VDC) input,3* 2+1 redundant 3000W power modular | ||
Service card | NT-TCA-SCG10 | 100G exchange card,10*QSFP28 interface | Choose according to actual business needs |
NT-TCA-CG10 | 100G service card,10*QSFP28 interface | ||
NT-TCA-XG24 | 10G service card,24*SFP+ interface | ||
NT-TCA-RTM-CG10 | 100G RTM card,10*QSFP28 interface | ||
NT-TCA-RTM-EXG24 | 10G RTM card,24*SFP+ interface | ||
TCA Visibility Embedded software system | NT-TCA-SOFT-PKG | must |


